Apache Spark has become a powerhouse in the world of big data processing. It’s a tool that has revolutionized the way we handle massive datasets, enabling faster and more efficient data processing and analysis. But where did Spark come from, and how did it evolve into the robust framework we know today? In this blog post, we’ll take a journey through the history of Apache Spark, exploring its origins and its remarkable evolution from concept to execution.
Table of Contents
The Birth of Apache Spark 🌟
Apache Spark’s journey began in 2009 at UC Berkeley with the advent of Mesos. At that time, the Apache Hadoop ecosystem lacked the YARN resource manager, which led to the inception of a remarkable class project AMPLab. Their audacious goal: to build a cluster management framework.
The Emergence of Mesos 🚀
In the year 2009, the emergence of Mesos marked a pivotal moment in the realm of distributed systems. It was conceived to orchestrate the execution and management of distributed applications, offering a promising alternative to traditional approaches.
Spark: A Testing tool for Mesos 🧠
It was within this innovative environment that Apache Spark was born, Apache Spark conceived initially as a tool to test the capabilities of Mesos. During this period, the dominant paradigm revolved around MapReduce, a model heavily reliant on disk storage. MapReduce’s limitations in terms of performance were evident.
But Spark was different, It embraced a memory-centric framework, where the majority of operations occurred within the realm of memory. This strategic shift was a deliberate response to the constraints that had long plagued the MapReduce model.
The Remarkable Reawakening 💡
However, after its initial inception as a Mesos testing tool, Spark briefly faded into the background, perceived merely as a subproject with a specific purpose—testing Mesos 😔.
But in 2011, something remarkable happened. The world took notice as it became evident that Spark had achieved a significant breakthrough in performance. It outpaced MapReduce by a wide margin, thanks to its unique in-memory execution model. 🚀
Apache Spark Takes Flight 🎉
In 2012, Apache Spark officially ascended to the status of an Apache project, solidifying its position as a revolutionary framework in the world of big data processing.
Unleashing Spark’s Superpowers 🚀
Apache Spark, like a superhero in the world of big data, boasts several incredible strengths that set it apart:
A Unified Stack 🧩
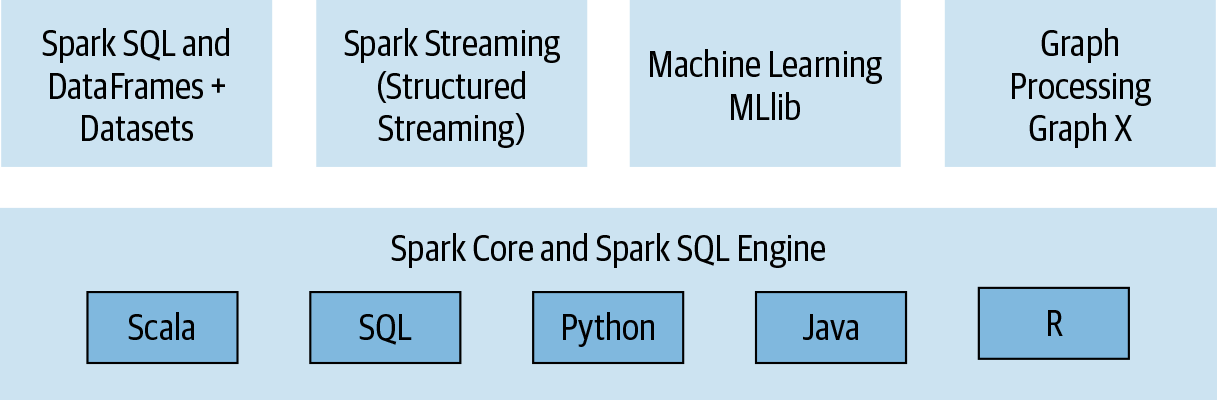
Spark’s unified stack brings together a multitude of data processing and analytics tools under one roof. Whether it’s batch processing, real-time stream processing, machine learning, or graph processing, Spark’s got it covered. This seamless integration of various data processing tasks makes Spark a true powerhouse.
Multilingual API Support 🌐
Spark speaks the language of developers! It offers APIs not just in its native Scala but also in Python, Java, and other languages. This multilingual support ensures that developers can work with Spark using the language they’re most comfortable with, making it an inclusive and versatile choice.
Memory-Based Speed
Spark’s brilliance doesn’t stop there; Unlike traditional models that rely heavily on disk storage, Spark operates predominantly in-memory. This memory-centric approach results in lightning-fast data processing and analysis, transforming the landscape of big data.
Spark Execution
Resources Management 💼
-
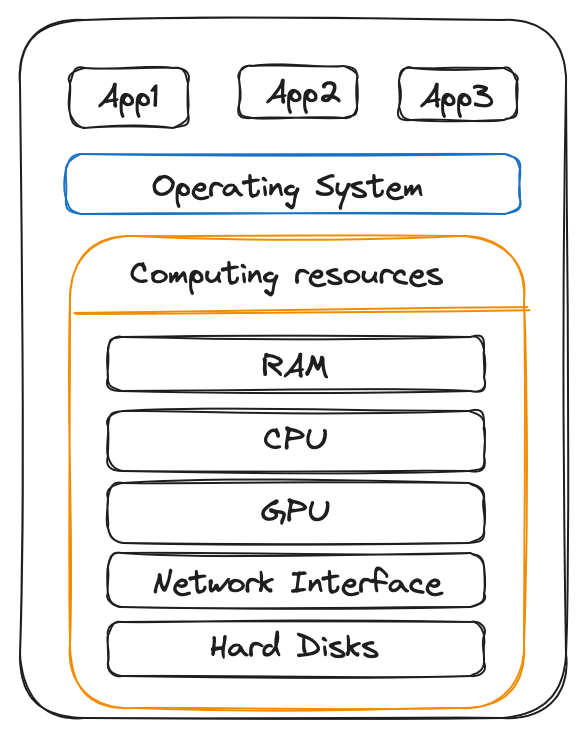
On a Single Machine:
- In a single-machine environment, we have computing resources (CPU, RAM, GPU…) along with an operating system (OS) and multiple applications, as mentioned in the figure below.
- The (OS) is responsible for resource management, which includes tasks such as resource scheduling and determining the allocation of resources (CPU, Memory, etc…) to individual applications. The allocation is based on available computing resources and the concurrent applications running on your computer.
-
In a Cluster:
- In a cluster, multiple working nodes are interconnected to form a cohesive computing environment. These nodes collaborate to perform distributed data processing tasks efficiently.
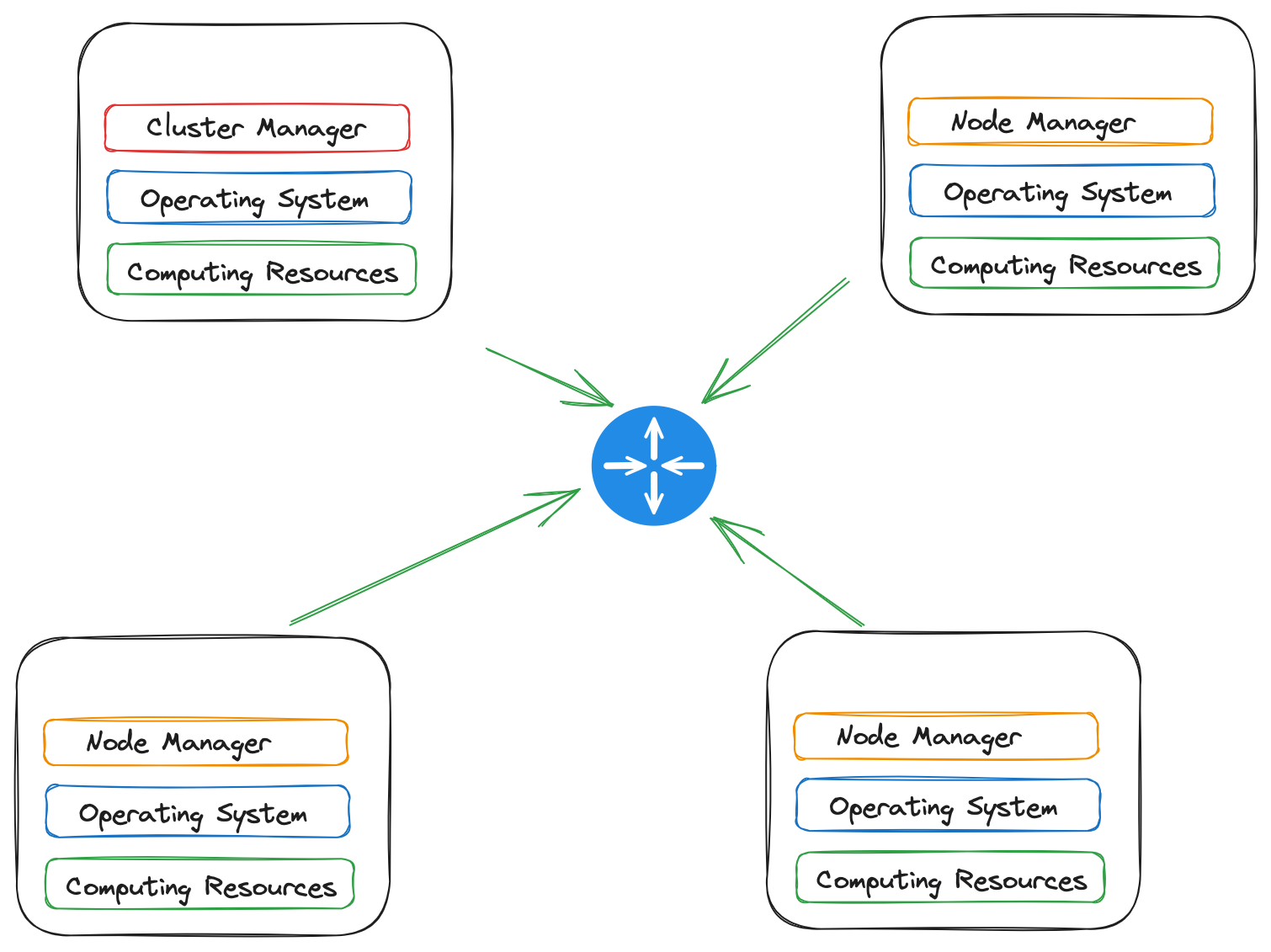
- In a cluster, there are dedicated applications for resource management that orchestrate the allocation of resources, These applications include:
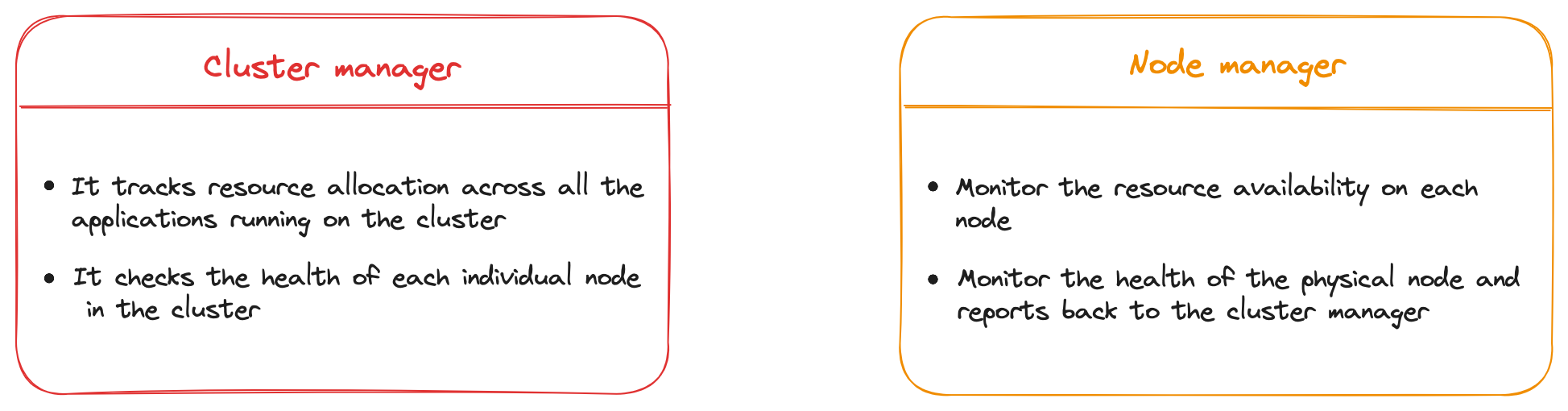
- Cluster manager
- Node manager
- In a cluster, multiple working nodes are interconnected to form a cohesive computing environment. These nodes collaborate to perform distributed data processing tasks efficiently.
Spark job components
To run your spark application in a cluster, you have to ask the cluster manager for the needed resources allocation. 🧙♂️ It’s the application master’s duty to ensure you get the resources you need. This “middleman” serves as the entry point to the cluster, making it all happen.
Running a Spark application in a cluster involves the following key components:
-
Spark application:
Each application running on the cluster has its own Application Master. The Application Master is responsible for negotiating resources with the Resource Manager, managing the application’s lifecycle, and ensuring that the application gets the resources it needs.
-
Spark driver process:
- Breaks down the Spark app logic into smaller tasks.
- Distributes and schedules the work among Spark executors.
- Tracks the status of all the Spark executors and monitor their progress
Note: If an executor crashes, it’s the driver process that requests the cluster manager for additional resources 🚒.
-
Spark executor processes:
- Execute the tasks assigned by the Spark driver process.
- Report their status back to the Spark driver
Spark Job Submission Workflow
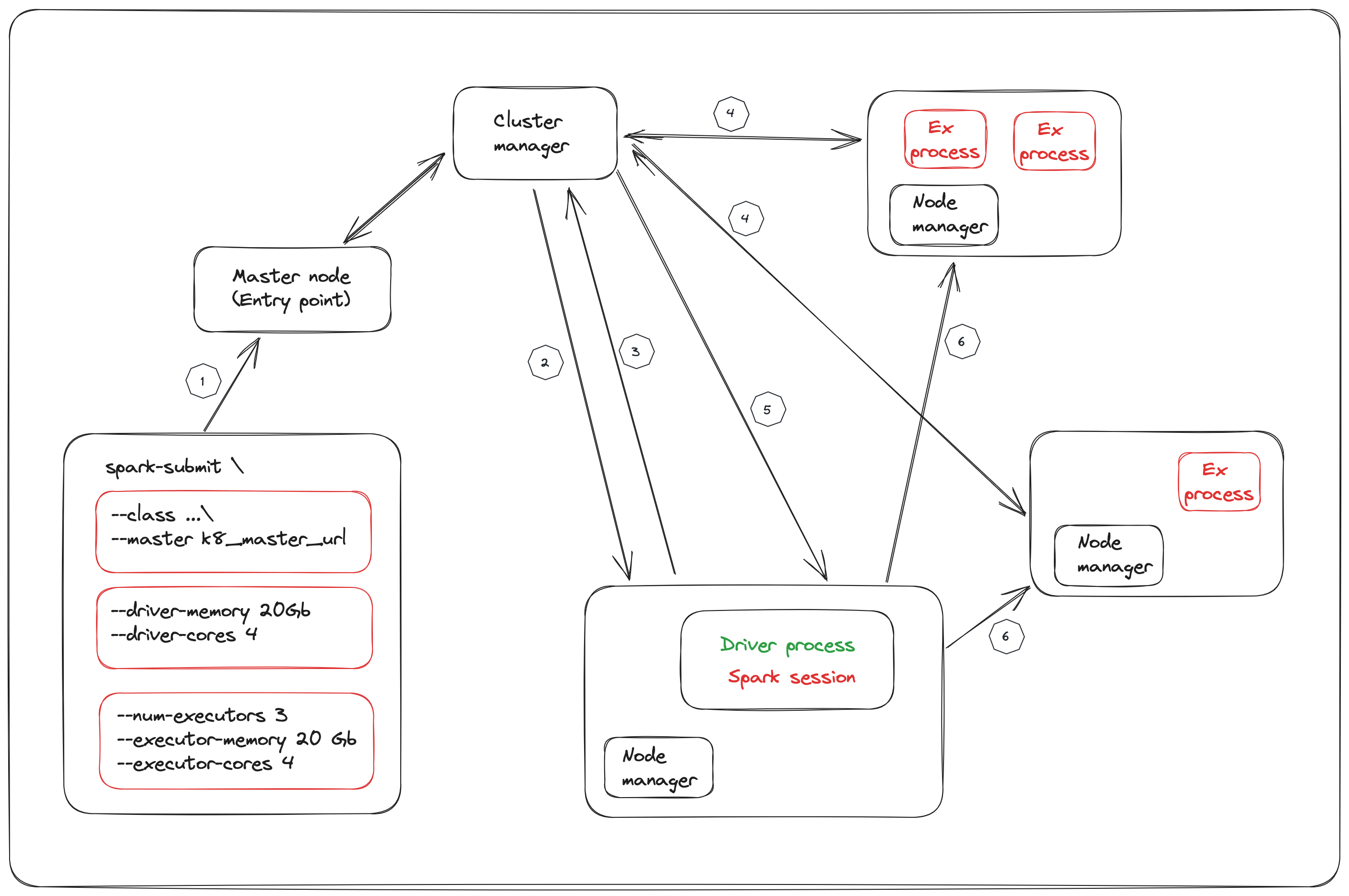 The above image illustrates the ⚙️ smooth process of Spark job submission:
The above image illustrates the ⚙️ smooth process of Spark job submission:
- You submit your Spark application to Master Node that interacts with the cluster manager and requests it to take charge of it and manage it.
Note: Master node refers to the node where you submit your Spark application.
- The Spark driver process needs to be started, so the cluster manager will request the node manager to start the driver process with the configuration we have specified during app submission.
If node manager has enough resources, then the Spark driver process will be created 🚀 .
-
The Spark driver process will request the cluster manager for additional resources to allocate resources for executor processes.
-
The cluster manager will request the node managers to create the executor processes, the node manager will create the executor process if it has enough resources.
Note: The node managers that have created executors send informations about their locations… to the cluster manager 📡.
-
The cluster manager inform back the driver process about the location of executor processes 📣.
-
Now, the Spark application is running and the Driver process starts to distribute tasks among the executors.
Note: All the Spark application logic will be sent to executors in the form of tasks to do the computation in parallel, so the spark driver process is the heart of spark app.
This orchestrated flow ensures that your Spark job is executed efficiently within the cluster.
Conclusion
Exploring Apache Spark’s history has revealed its innovative origins and the ‘why’ behind its existence 🌱. Understanding its origins provides a deeper appreciation for the impact it has on the world of data processing. In this article, we’ve tried to cover essential aspects of Apache Spark, from its history to its submission workflow. I hope you’ve found this article both informative and insightful, if you have any questions or comments, please reach me out. Thanks for reading!